VGGT Paper | Paper
The VGGT (Visual Geometry Grounded Transformer) is a paper that won best paper in the CVPR25, it introduced a strategy that could infer 3D attribute of a scene from the one or more image views of the scene completely independent of the camera intrinsics. Unlike the classical Photogrammy techniques of infering 3D attributes of the scene using a calibrated camera’s intrinsics, this doesn’t require it, reducing inductive biases and thereby improving the visual geometry efficiency. Similar stategies already existed that use traditional neural networks in place of traditional geometry methods like Bundle Adjustments for feature tracking, monucular depth estimation and 3D attribues computuation. Recent contributions like DUSt3R, MASt3R existed but these require two images at one and also include a post-processing step for fusion. However in place of this, this just requires only a feed forward transformer network fro the entire processing. VGGT predicts a full set of 3D attributes, including camera parameters, depth maps, point maps, and 3D point tracks in a single pass. The model consists of approximately 1.2 billion parameters in total. VGGT paper introduces VGGSfM that is to practically replace the classical SfM pipeline of COLMAP etc. It states to be more accurate.
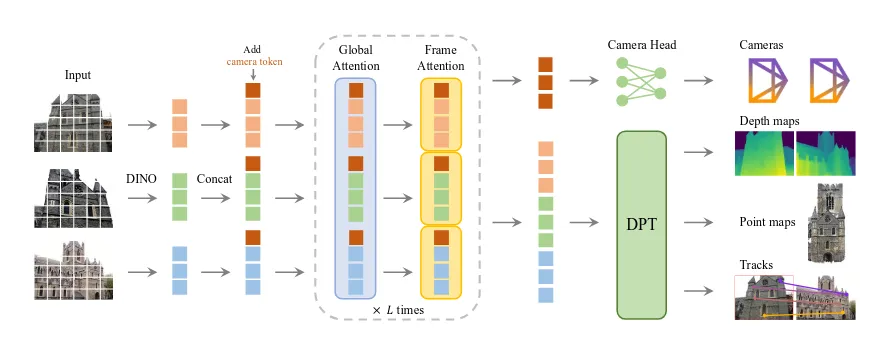
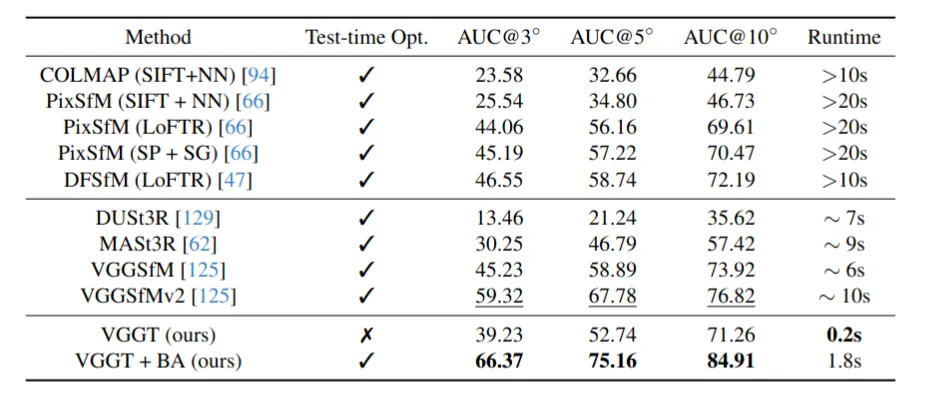
In my opinion, the key advantage here is that it does not require a post-processing step like bundle adjustment, which makes it ideal for SLAM since everything runs in real time. Because it is independent of camera intrinsics, different cameras can be used interchangeably. Since this is a differentiable feed-forward neural network, inference on accelerators is practically instantaneous while still providing highly detailed 3D parameters such as camera poses. I think this approach, inspired by DUSt3R and particularly effective when paired with Gaussian splatting, is the missing piece needed to move beyond classical over-parameterized point-map-based SLAM and toward much more accurate localization and real-time 3D RGB map rendering.